Summarized information about kafka from various sources.
What is Kafka?
Kafka is a distributed publish/subscribe messaging system with guarantees around speed scalability and durability.
Kafka is designed for distributed high throughput systems. Kafka tends to work very well as a replacement for a more traditional message broker. In comparison to other messaging systems, Kafka has better throughput, built-in partitioning, replication and inherent fault-tolerance, which makes it a good fit for large-scale message processing applications.
Kafka can be considered a combination between message queue and publish-subscribe pattern
Publish/Subscribe Messaging
Publish/Subscribe messaging is a pattern where you have a sender(publisher) of data(message). This message is not directed specifically to a reciever, instead it is tagged somehow. On the other end you have the receiver(subscriber), which subscribes to receive messages with certain tags. In between the publisher and subscriber we usually have a broker(server) which is a centralized point for messages to be published and subscribed to.
For example, a normal Metrics handling system would look something like this:
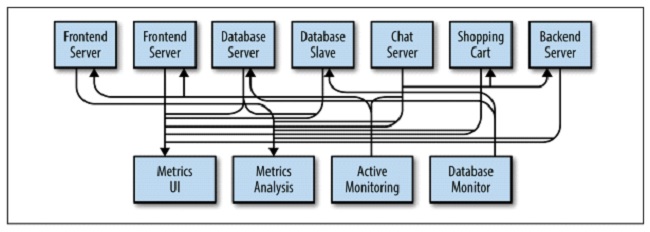
By implementing a Pub/Sub system it would look something like this:
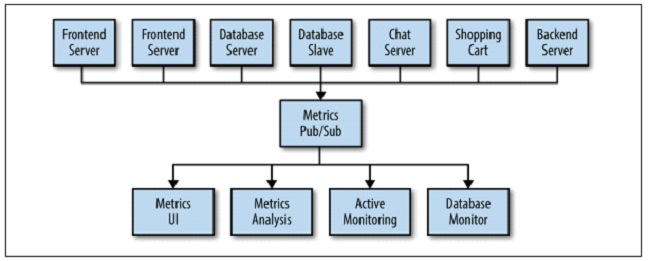
As our application grows we would like to add more pub/sub systems for various services:
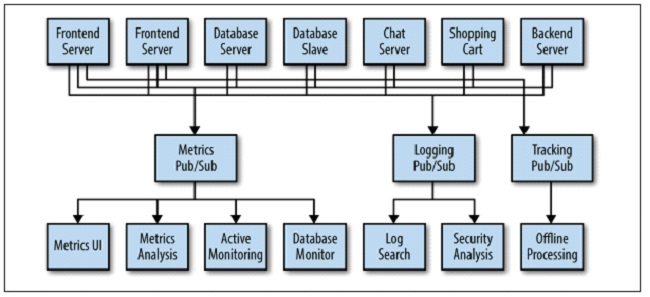
Kafka key terms
Producer
- Producers create new messages.
- Producers publish messages(data) to topics
- Producers are by default responsible for choosing which record to assign to which partition within the topic. This is by default done by round-robin or according to some semantic partition function(based on some key in the record)
Consumer
- Consumers Reads messages(data) from Kafka clusters(group of servers)
- Consumers subscribes to one or more topics and consume published messages by puling data from servers.
- Consumers consume messages in the order they were produced.
- Consumers keeps track of what messages it has consumed by keeping track of the messages offset.
- Consumers are labeled with a consumer group name, and each record published to a topic is sent to one consumer in every subscribing consumer group.
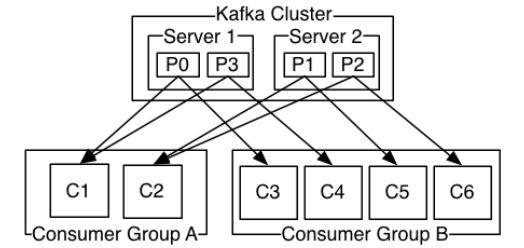
- Consumer instances can be in separate processes or on separate machines.
- If all the consumer instances have the same consumer group, the records will be effectively load balanced over the consumer instances
- If all the consumer instances have different consumer groups, each record will be broadcast to all the consumer instances
- Consumers are very memory cheap, they can come and go without much impact on the cluster or on other consumers.
- Each consumer holds metadata on the offset/position in the partition log
- Normally a consumer advances its offset linearly as it reads records, but it can consume records in any order it likes. For example, a consumer can reset to an older offset to reprocess data from the past or skip ahead to the most recent record and start consuming from “now”.
- A consumer instance sees records in the order they are stored in the partition log
Consumer group
- Each consumer group consists of many consumer instances for scalability and fault tolerance
- A consumer group is a “logical subscriber” to topics.
- Usually a small number of consumer groups subscribe to a topic
- In Kafka the subscriber is a cluster of consumers instead of a single process.
- There cannot be more consumer instances in a consumer group than partitions.
- Kafka guarantees that a message is only ever read by a single consumer in the group.
Broker (Kafka Servers)
- A single Kafka server is called a broker.
- A broker receives messages from producers, assigns offsets, and commits the messages to storage on disk.
- A broker also services consumers, responding to fetch requests for partitions and responding with the message that has been committed to disk.
- Depending on hardware and its performance characteristics, a single broker can easily handle thousands of partitions and millions of messages per second.
- Brokers holds a default retention period setting for topics.
- Kafka brokers are designed to operate as part of a cluster.
- If it’s a cluster, one broker will function as cluster controller(Automatically selected from live server)
- The controller assigns partitions to brokers, and monitors for broker failures.
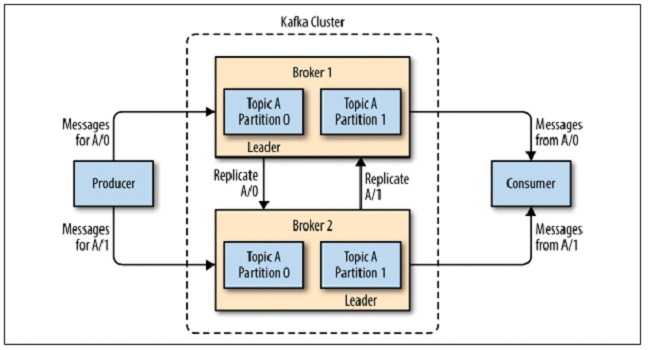
Cluster
- Kafka is run as a cluster on one or more servers(brokers) that can span multiple data centers.
- A cluster consists of servers hosting partitions. that represents topics
- Kafka cluster stores streams of records in categories called topics
- As the application grows, having multiple clusters have several advantages:
- Segregation of types of data
- Isolation for security requirements
- Multiple data centers(regions, disaster recover)
- It’s often required to copy data between datacenter clusters. -Ex: If a user changes public info in their profile it has to change in all data centers.
Topics
- A topic is a stream of messages belonging to a particular category that stores data.
- Think of it as a table in a DB or a folder in a file system.
- Each topic needs at least one partition.
- A Topic is a category or feed name to which records are published.
- Topics are always multi-subscriber(A topic can have zero, one, or many consumers that subscribe to data written to it)
- Each Topic retention period config can be customized.
- Each topic has a partition log that looks like this:
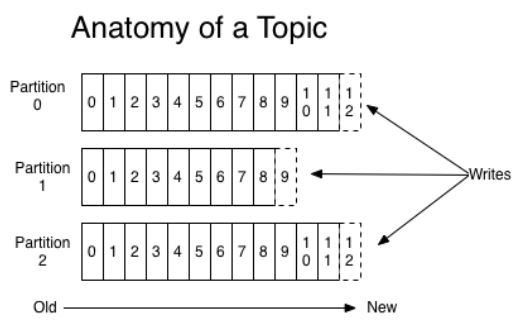
Partition Log
- Is a group/log of partitions for each topic
- The log partitions have several purposes.
- To allow the log to scale beyond a size that fits on a single server. Each partition must fit on the servers that host it, but a topic can have many partitions so it can handle a big amount of data.
- They act as the unit of parallelism.
Partition
- A partition is an ordered, immutable sequence of records.
- Partitions are continually appended to a structured commit log
- Each record in the partition is assigned a unique sequential id number called the offset
- Partitions is how Kafka provides redundancy and scalability.
- Partitions can be stored on different servers.
- Kafka assigns the partitions of a topic to the consumer in a consumer group. Hence, each partition is consumed by exactly one consumer in the group.
Partition Offset
- A unique sequential id number assigned to each record in a partition.
- Automatically added by Kafka as messages are produced.
- By storing the offset of the last consumed message for each partition, a consumer can stop and restart without losing its place.
Record/Message/row
- Every record consists of a key, a value, and a timestamp.
- A Kafka cluster persists all published records throughout the configured retention period
- Even if a record is consumed it will persist throughout the configured retention period
- Example: If the retention policy for a record is set to two days, then after being published it is available for consumption for two days. After that it will be discarded to free up space.
- The retention policy can also be a certain file-size (e.g., 1GB and message will be deleted)
Distribution
- Partitions are distributed over the Kafka clusters.
- Each server handles data and requests for a share of the partitions.
- Each partition is replicated across a configurable number of servers for fault tolerance.
- Each partition has one server that acts as the “leader”, and zero or more servers which act as “followers”
- The leader handles all read and write requests for the partition.
- The followers passively replicate the leader.
- If the leader fails, a follower will automatically become the new leader.
- Each server acts as a leader for some partitions, and a follower for some partitions.
- All consumers and producers operating on the partition must connect to the leader.
Geo-Replication
- Kafka MirrorMaker provides geo-replication support for clusters.
- Messages are replicated across multiple data centers or cloud regions.
- Usually used in two cases
- Active/passive scenarios for backup/recover
- Active/Active scenarios to place data closer to your users, or support data locality requirements.
- At its core MirrorMaker is simply a Kafka consumer and producer linked together with a queue.
- Messages are consumed from one Kafka cluster and produced for another.
Batches
Messages in Kafka are written in batches. A batch is a collection of messages which is being produced/published to the same topic and partition. A larger batch can handle more messages per unit of time, but it takes longer for an individual message to be produced.
Schemas
It is recommended to have a set structure or schema for messages so that it can be easily understood. JSON and XML are easy to use and human-readable. But they lack robust type handling and compatibility between schema versions. Many Kafka developers use Apache Avro for its compact serialization format, schemas that are separate from the message payloads, strong data typing, and schema evolution with both backward and forward compatibility.
A consistent data format is very important for decoupling.
Commit Log
Since Kafka is based on the concept of a commit log, database changes can be published to Kafka and applications can easily monitor this stream to receive live updates as they happen.
This change-log stream can also be used for replicating database updates to a remote system. Or combine changes from multiple applications into a single database view.
Streams
A single topic of data, regardless of the number of partitions. A single stream of data moving from producers to the consumers. Usually used when discussing stream processing (Real-time operation on messages)
Kafkas 5 Core APIs
- Producer API
- Consumer API
- Streams API
- Connect API
- AdminClient API
When to use what
- Kafka Producer API: Applications directly producing data (ex: clickstream, logs, IoT).
- Kafka Consumer API: Read a stream and perform real-time actions on it (e.g. send email…)
- Kafka Streams API / KSQL: Applications wanting to consume from Kafka and produce back into Kafka, also called stream processing. Use KSQL if you think you can write your real-time job as SQL-like, use Kafka Streams API if you think you’re going to need to write complex logic for your job.
- Kafka Connect Source API: Applications bridging between a datastore we don’t control and Kafka (ex: CDC, Postgres, MongoDB, Twitter, REST API).
- Kafka Connect Sink API: Read a stream and store it into a target store (ex: Kafka to S3, Kafka to HDFS, Kafka to PostgreSQL, Kafka to MongoDB, etc.)